Большинство современных процессоров (CPU - Central Processor Unit) являются многоядерными, то есть включают в свой состав несколько независимых физических ядер, которые могут работать одновременно. Кроме того, включение технологии «Hyper-threading» позволяет в 2 раза увеличить количество логических ядер, которые определяются операционной системой.
FDS может быть запущена в многопоточном режиме (т. е. с параллельной обработкой данных), когда вся работа разделяется между несколькими ядрами процессора одного компьютера, либо между процессорами нескольких компьютеров, объединенных в одну сеть.
При увеличении числа потоков, как правило (но не всегда), растет производительность и сокращается время выполнения моделирования. Рост производительности может наблюдаться только если количество потоков не превышает число логических ядер.
Есть две технологии, позволяющие запустить FDS в многопоточном режиме, которые могут использоваться совместно:
- OpenMP (Open Multi-Processing). С помощью этой технологии возможно задействовать несколько ядер процессора компьютера, на котором осуществляется моделирование.
- MPI (Message Passing Interface). С помощью этой технологии возможно задействовать несколько ядер процессора компьютера, на котором осуществляется моделирование, или процессоры нескольких компьютеров, находящихся в локальной сети.
Прежде чем перейти к разбору стратегии запуска FDS в Fenix+ 3, необходимо сказать несколько слов о том, как в FDS происходит моделирование.
Моделирование в FDS происходит в расчетном домене - объеме пространства, развитие пожара в котором интересует. Расчетный домен состоит из одного или нескольких элементарных объемов - сеток. Сетка - это объем пространства, имеющий форму прямоугольного параллелепипеда:
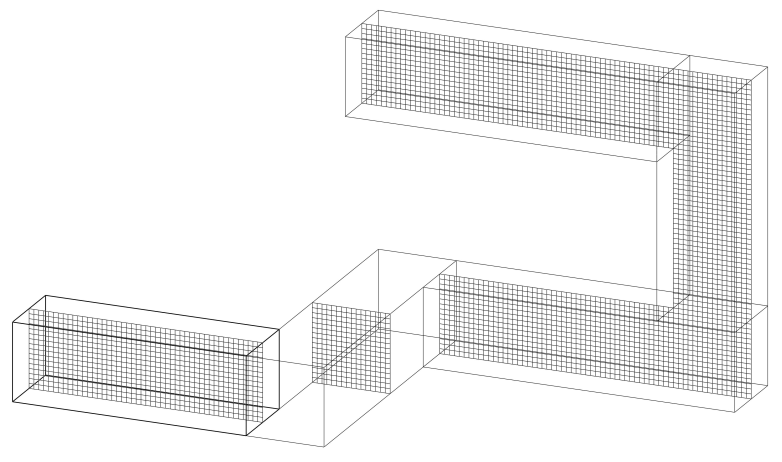
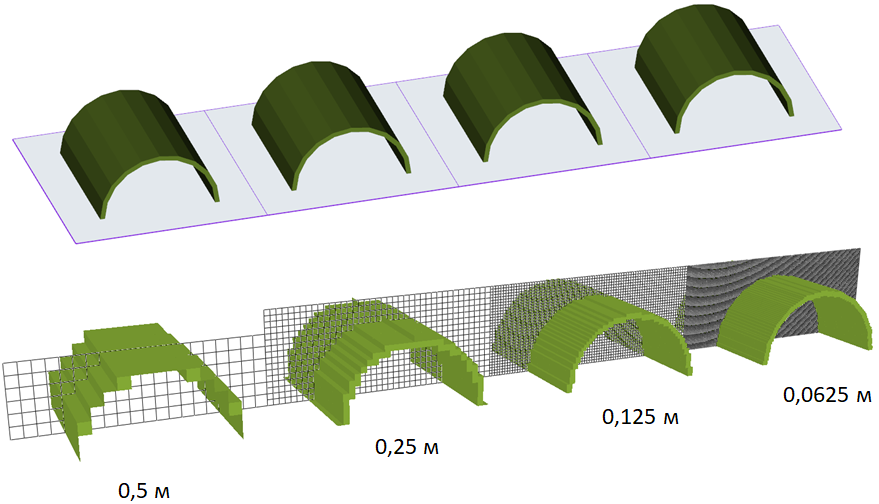
Каждая сетка делится на прямоугольные ячейки. Размер ячеек (и, соответственно, их количество) определяет насколько точно объекты будут представлены в FDS и насколько точнее будет проведено моделирование. Чем меньше размер ячейки, тем точнее объекты представляются в FDS:
Во входном файле для FDS каждая сетка представляется группой параметров MESH:
&MESH IJK=10,20,30 XB=0.0,1.0,0.0,2.0,0.0,3.0 /
где параметр IJK определяет количество ячеек, на которое делится сетка вдоль каждой стороны, а XB определяет линейные размеры сетки. Соответственно, в примере выше сетка делится на 6000 (10*20*30) ячеек.
Количество ячеек в сетке - один из важнейших параметров, который определяет время выполнения моделирования. Чем больше количество ячеек, тем больше время выполнения моделирования.
Далее под размерами сетки подразумеваем не линейные размеры сетки, а количество ячеек в ней. То есть, “большая сетка“ - это сетка с большим количеством ячеек.
Запуск в многопоточном режиме с помощью OpenMP
Чтобы использовать технологию OpenMP для многопоточного моделирования достаточно перед запуском FDS задать переменной окружения OMP_NUM_THREADS значение, равное желаемому количеству потоков.
После запуска FDS в многопоточном режиме с помощью технологии OpenMP в ОС Windows в программе “Монитор ресурсов” можно будет увидеть один процесс “fds” и несколько потоков, ассоциированных с ним:
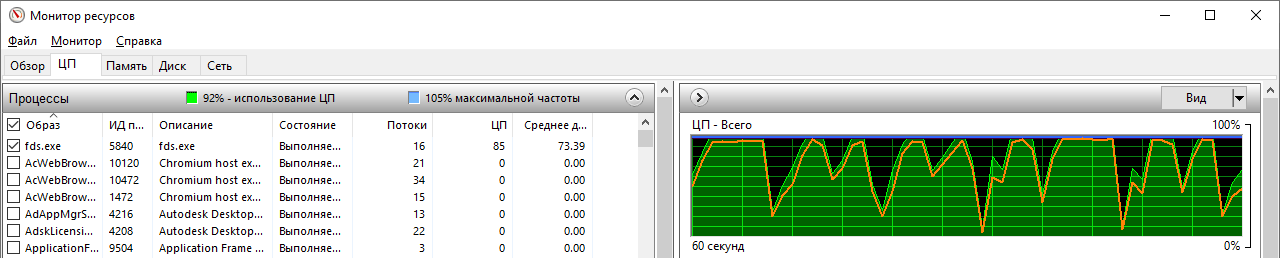
Если расчетный домен состоит из нескольких сеток, то они будут последовательно обрабатываться в рамках одного процесса.
Запуск в многопоточном режиме с помощью MPI
Чтобы использовать MPI для многопоточного моделирования весь расчетный домен должен быть разделен на несколько сеток. При этом каждая сетка обрабатывается одним MPI процессом, назначенным для нее. Кроме того возможно назначить нескольким сеткам один и тот же MPI процесс. Это полезно когда расчетный домен представлен несколькими большими сетками и множеством маленьких. Большие сетки будут обрабатываться собственными MPI процессами, в то время как несколько маленьких сеток будут обрабатываться одним и тем же MPI процессом. Обработка нескольких сеток одним MPI потоком позволяет сократить объем взаимодействия между MPI процессами. MPI процесс, который будет обрабатывать конкретную сетку, определяется параметром MPI_PROCESS группы параметров MESH:
&MESH ID='mesh1', IJK=..., XB=..., MPI_PROCESS=0 /
&MESH ID='mesh2', IJK=..., XB=..., MPI_PROCESS=1 /
&MESH ID='mesh3', IJK=..., XB=..., MPI_PROCESS=1 /
&MESH ID='mesh4', IJK=..., XB=..., MPI_PROCESS=2 /
&MESH ID='mesh5', IJK=..., XB=..., MPI_PROCESS=3 /
&MESH ID='mesh6', IJK=..., XB=..., MPI_PROCESS=3 /
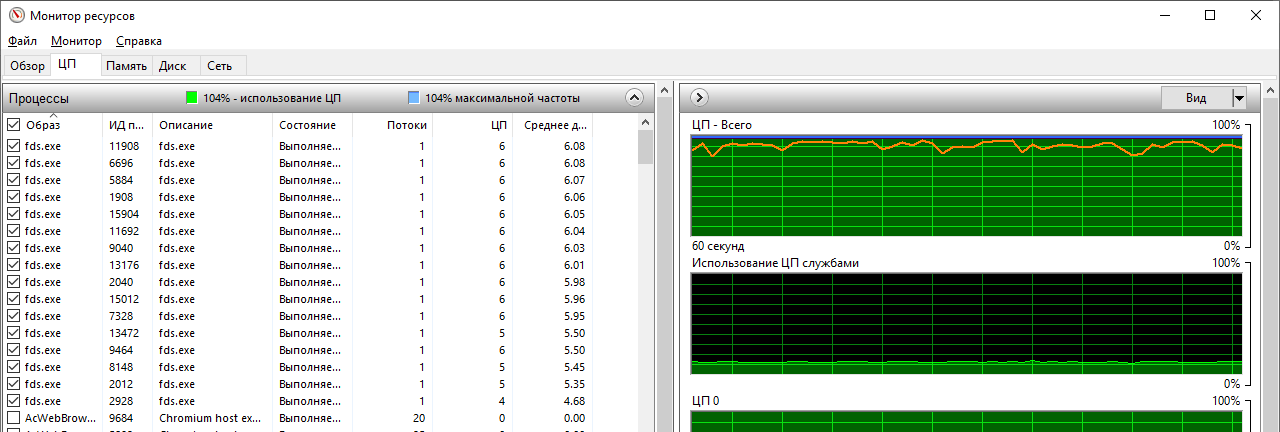
После запуска FDS в многопоточном режиме с помощью MPI на одном компьютере в ОС Windows в программе “Монитор ресурсов” можно будет увидеть несколько процессов “fds”:
Сравнение ускорения моделирования с помощью OpenMP и MPI
Под словами “ускорение моделирования“ будем подразумевать во сколько раз время выполнения моделирования в многопоточном режиме меньше времени выполнения моделирования без применения технологий многопоточной обработки.
Чтобы определить какая технология многопоточной обработки позволяет добиться наибольшего ускорения моделирования был рассмотрен следующий сценарий:
- расчетный домен представляет собой прямоугольный параллелепипед размерами 50*50*5 метров
- размер ячейки сетки равен 0,125 м
- в центре расчетного домена расположена пожарная нагрузка площадью 16 м. кв.
- время моделирования составляет 10 секунд
- при моделировании с применением MPI расчетный домен разбивался на одинаковые сетки, каждой из которых назначался свой MPI процесс.
То есть в расчетном домене для этого сценария 6400000 ячеек. Для моделирования этого сценария требуется примерно 6,6 Гб оперативной памяти.
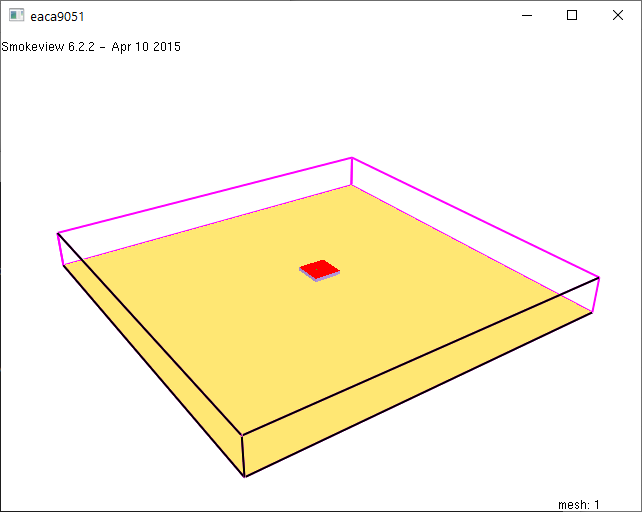
Моделирование проводилось на компьютере с 8-ми ядерным процессором AMD Ryzen 7 2700 (16 логических процессоров). Время проведения моделирования составляло от 30 до 100 минут.
На графике ниже показано изменение ускорения моделирования с увеличением количества MPI процессов или OpenMP потоков.
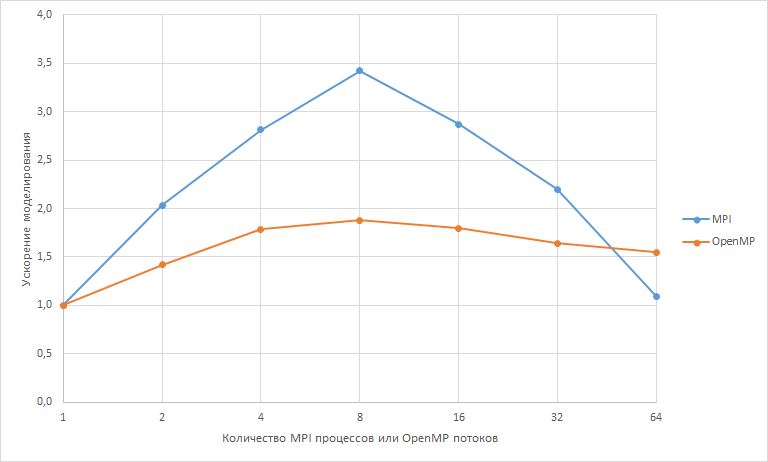
Видно, что сначала увеличение количества потоков приводит к ускорению моделирования. Однако при количестве потоков больше 8-ми и для MPI и для OpenMP ускорение уменьшается. В первую очередь это связано с увеличением объема взаимодействия между процессами.
Полученный результат не означает, что для любого сценария при выполнении моделирования на любом процессоре оптимальное количество потоков равно 8-ми.
Можно лишь утверждать, что для рассмотренного сценария при проведении моделирования на таком процессоре оптимальное количество потоков равно 8-ми.
Для каждого сценария при моделировании на определенном процессоре оптимальное количество потоков будет разное. Оптимальное количество потоков зависит от размера сеток и их взаимного расположения, количества ядер процессора.
Бессмысленно задавать количество потоков для моделирования, превышающее количество логических ядер процессора. В этом случае ускорение гарантированно будет меньше максимально возможного.
Проведенный эксперимент показывает, что для ускорения моделирования целесообразнее использовать MPI. При этом нужно стремиться к тому, чтобы суммарный размер сеток, обрабатываемых каждым MPI процессом был примерно одинаков.
Вопросы запуска FDS, в том числе и в многопоточном режиме, используя MPI и OpenMP, подробно разобраны в руководстве пользователя FDS. Кроме того, в руководстве также рассматривается эффективность каждого подхода, где делается аналогичный вывод о предпочтительности MPI. Рекомендуем ознакомиться с частью 3 (Chapter 3 Running FDS) руководства пользователя FDS для получения дополнительной информации по этой теме.
Запуск FDS в многопоточном режиме в Fenix+ 3
Как было показано выше, предпочтительным способом запуска моделирования в многопоточном режиме является MPI. Именно с помощью MPI Fenix+ 3 запускает моделирование с использованием такого количества MPI процессов, которое пользователь задал в параметрах моделирования пожара для сценария. Перед запуском FDS Fenix+ 3 подготавливает входной файл для FDS таким образом, чтобы расчетный домен был разбит на необходимое количество сеток и каждой сетке был назначен свой MPI процесс. Далее остановимся подробнее на процедуре подготовки входного файла для многопоточного моделирования, знание которой позволит выбирать более оптимальное количество потоков для моделирования.
Алгоритм формирования групп MESH
Для определения объема, в котором необходимо моделировать динамику развития пожара в Fenix+ 3 предназначен инструмент “Область расчета“. В сценарии можно разместить несколько областей расчета. Их размеры и другие параметры (размер ячейки, состояние открытых граней) могут быть разными. Расположение областей расчета друг относительно друга может быть абсолютно произвольным: они могут пересекаться, касаться или вообще не иметь общих точек.
В некотором роде, область расчета в сценарии проекта Fenix+ 3 соответствует сетке (группе MESH) во входном файле FDS. В простейших сценариях соответствие может быть однозначное. Но в общем случае соответствие лишь приблизительное, так как, например, одна область расчета может во входном файле FDS формировать несколько групп MESH или, даже наоборот, несколько областей расчета может преобразоваться в одну группу MESH.
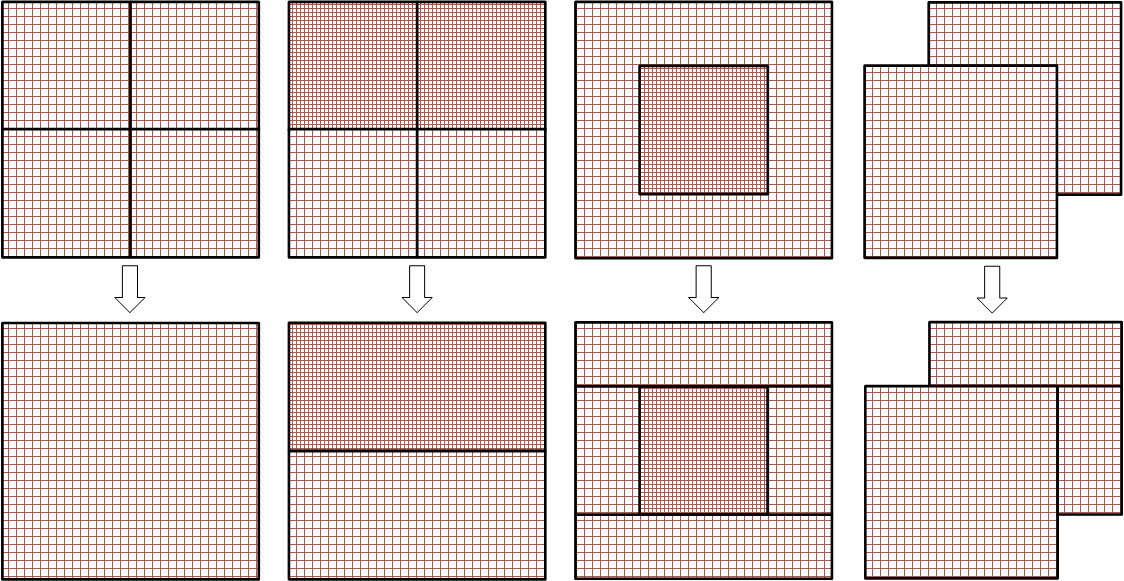
Преобразование областей расчета в сетки состоит из следующих основных этапов:
- “Объединение“. Все области расчета с ячейкой одного размера по возможности объединяются в более крупные области. При этом:
- устраняются пересечения областей расчета (это может приводить к некорректным результатам в области пересечения). Если пересекаются области с разными размерами ячейки, то из области с крупным размером ячейки исключается пересечение с областью расчета с мелким размером ячейки, а оставшаяся часть разбивается на несколько прямоугольных областей.
- увеличиваются области расчета в направлениях, где количество ячеек меньше 3 (этот случай очень редкий и на практике может возникнуть только из-за ошибки при размещении области расчета).
- “Разбиение“. Eсли количество потоков, которое пользователь хочет использовать для моделирования, больше количества получившихся на первом этапе областей, то те из них, в которых больше всего ячеек, разбиваются пополам в направлении с наибольшим количеством ячеек. Разбиение прерывается, если:
- количество имеющихся областей равно или больше желаемого количества потоков.
- границы областей, которые получились бы при разбиении самой крупной области, попадают на одну из групп VENT во входном файле FDS (группы VENT располагаются в месте расположения очага пожара или клапана дымоудаления)
- больше нет MESH, которые можно разбить. После этого этапа получаются области, полностью соответствующие сеткам во входном файле FDS. Так как разбиение может прерваться, то количество сеток может быть меньше желаемого количества потоков.
- “Балансировка“. Всем получившимся сеткам назначается MPI процесс, который будет их обрабатывать. Для этого:
- выбирается самая крупная сетка, которой ещё не назначен MPI процесс.
- выбирается MPI процесс, которому назначены для обработки сетки с наименьшим суммарным объемом.
- выбранной сетке назначается выбранный MPI процесс.
Примеры формирования групп MESH
В примерах ниже предполагается, что в сценарии области расчета с размерами ячейки, отличающимися в два раза.
На примерах ниже показан результат выполнения этапа “Объединение“ при формировании групп MESH для различных взаимных расположений областей расчета.
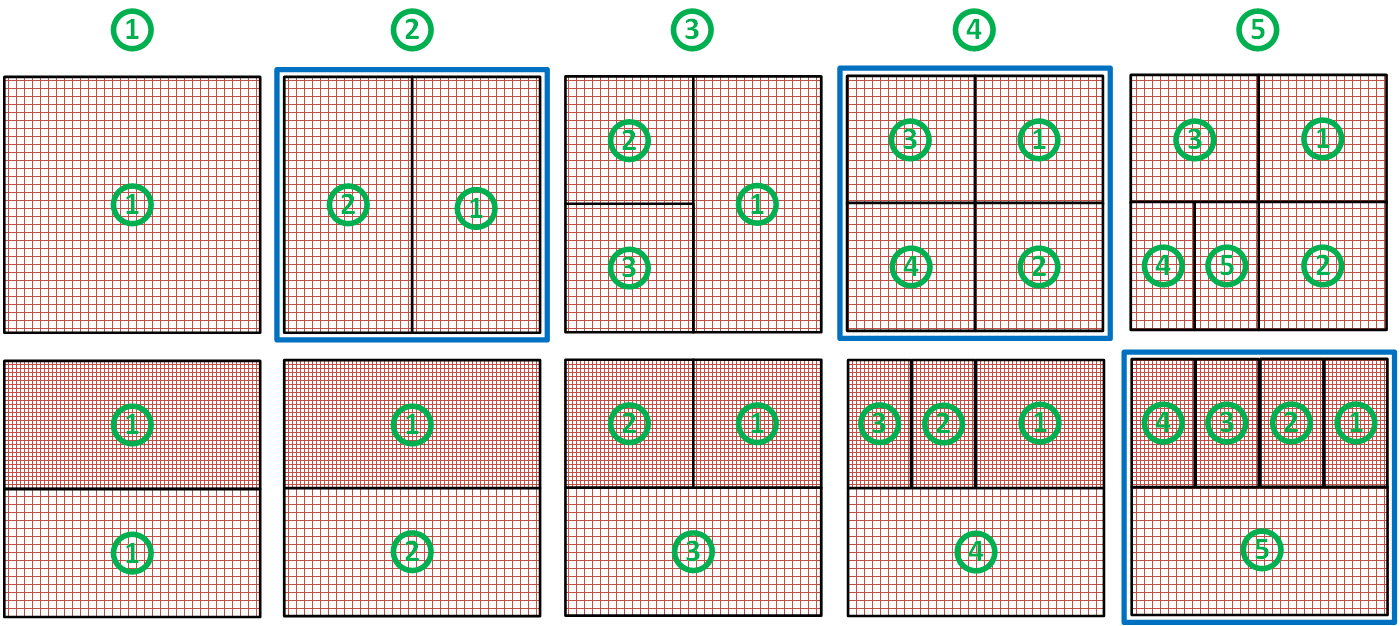
На следующих примерах показан результат выполнения этапов “Разбиение“ и “Балансировка“ для различного количества потоков моделирования (число сверху) в случае, если количество сеток после этапа “Разбиение“ не превышает количество потоков.
Над каждой сеткой показан номер MPI процесса, который назначен для обработки этой сетки.
Синим квадратом обведены наиболее сбалансированные случаи когда каждый MPI поток обрабатывает сетки одинакового размера (с одинаковым количеством ячеек).
На следующих примерах показан результат выполнения этапа “Балансировка“ для 2-х потоков моделирования в случае, когда количество сеток после этапа “Разбиение“ превышает количество потоков.
Над каждой сеткой показан номер MPI процесса, который назначен для обработки этой сетки.
Синим квадратом обведены наиболее сбалансированные случаи когда каждый MPI поток обрабатывает сетки одинакового размера (с одинаковым количеством ячеек).
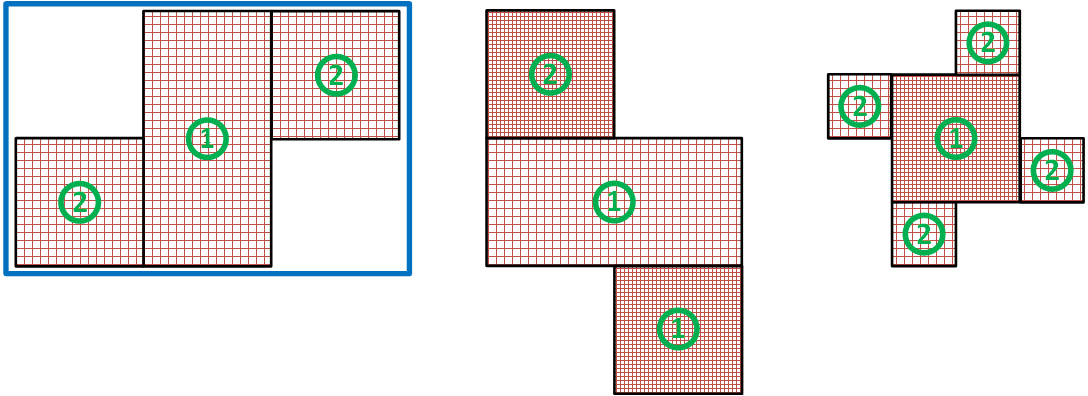
На всех примерах выше алгоритм формирование сеток показан в двумерном случае. Но, следует иметь в виду, что во всех трех направлениях алгоритм работает одинаково.